Audio files containing speech, such as podcasts, must have a text alternative, i.e. an alternative in text format for users who cannot listen to the file for one reason or another. When available online, a text alternative improves the retrievability of information in an audio file, as search engines can index speech content via the text alternative. For example, it is easier to reference podcasts if you provide text alternatives, as it is easier to reference a text alternative than an audio source. Also, it is easier to check source information from a text alternative than an audio file.
It is easier to create a text alternative if you first create a raw version of the text content using voice recognition. Word’s browser version in the MS Office 365 suite features a handy tool for this.
How to create and fix automatic text alternatives in Word’s browser version
- Open a new empty file in the MS Word browser version. (You can access it using your University of Oulu or Oamk account.)
- Select Transcribe (Litteroi) from the Home (Aloitus) ribbon.
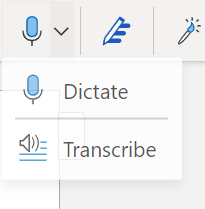
- Set the language according to the language of the audio file and upload the audio file to Word in MP3 format, for example. Press the Upload Audio button to proceed to upload.
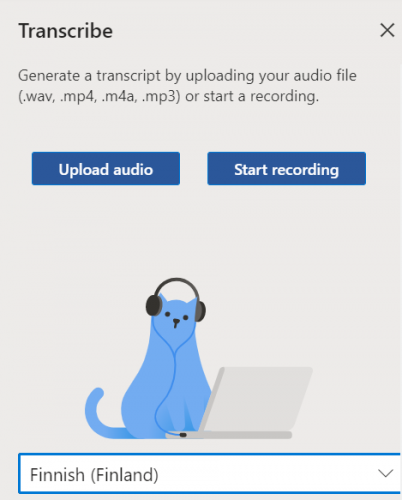
- If your file is long, it may take several minutes to convert it to text. The program prompts you to leave the browser window open for that time.
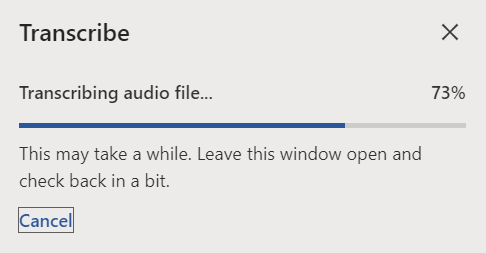
- When the work is completed, you will see the finished text on the screen. Next, move them to your Word file. Press the Add to Document button and select the desired option. If there are multiple speakers, select the With Speakers option. (If timestamps are required for some compelling reason, you can select the With Speakers and Timestamps option. However, timestamps are typically not added, as they are often unnecessary information that impairs the experience of screen reader users.
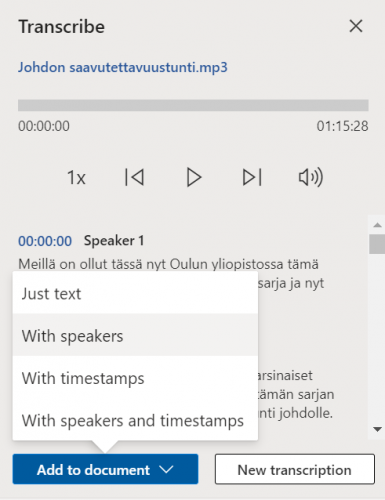
- If there are multiple speakers, Word can distinguish between them fairly well. Speakers are named in the file as Speaker 1, Speaker 2, etc. You can replace these with the names of the speakers using the Replace (Korvaa) feature on the Home (Aloitus) ribbon.
- Replace the Transcript heading with the title of your audio file, and then change the names of the speakers. You can then merge the paragraphs by the same speaker together, i.e. delete the extra consecutive mentions: it is enough to mention the name of the speaker when the speaker changes.
- Finally, check the text using the proofreading tool and correct any errors.
- Automatic speech recognition is not perfect, and there are typically errors with compound words.
- Proper nouns will be in small print, so you need to fix them.
- Numbers may need to be rewritten.
- Abbreviations and foreign language terms often require correcting.
- Depending on the speaker, the speech may contain unnecessary fillers or awkward sentence structures: in the case of a standard text alternative to a podcast, these can and should be corrected to be clearer because the idea is to convey the main message unambiguously. (Verbatim transcription is mainly suitable for linguistic research data and the like.)
- If the audio file contains music or other sounds, you can include them in brackets in the section of the paragraph where they are audible. For example, if your podcast starts with a piece of music, you can indicate it as follows: (music).
- Once you have completed the text, you can publish the text alternative as a link in connection with your audio file. The best format to use is the web page: publish the text alternative online if possible. If this is not possible, an accessible file is another option. (However, note that a personal OneDrive is not a good place for long-term use, as the account and its file retention period depend on the validity of the user ID.)